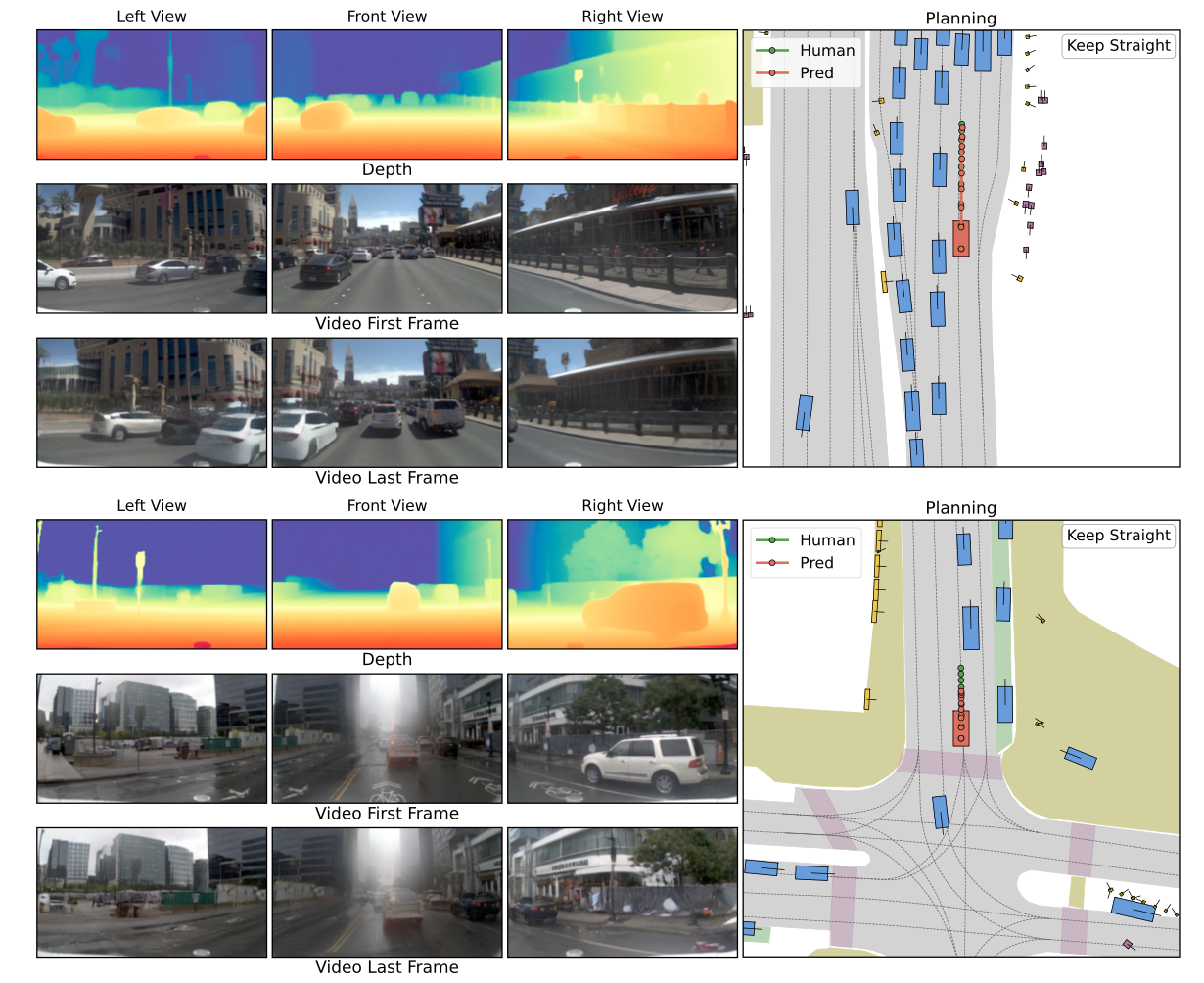
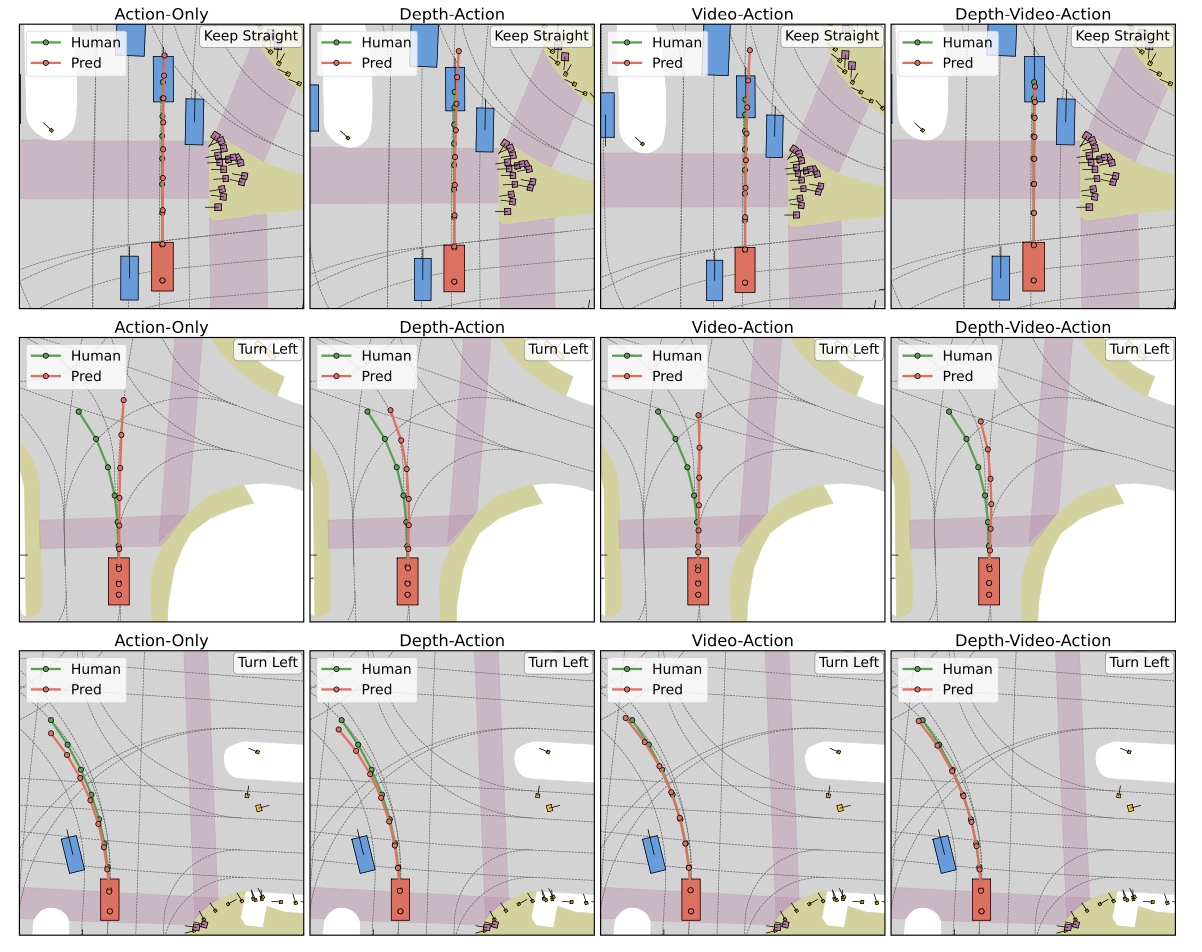
DriveDreamer-Policy couples a large language model (Qwen3-VL-2B) with three lightweight generative experts, connected through a fixed-size query bottleneck. The LLM processes multi-view images, language instructions, and current action context alongside learnable depth, video, and action queries. The resulting embeddings condition three modular experts for depth, video, and action generation.
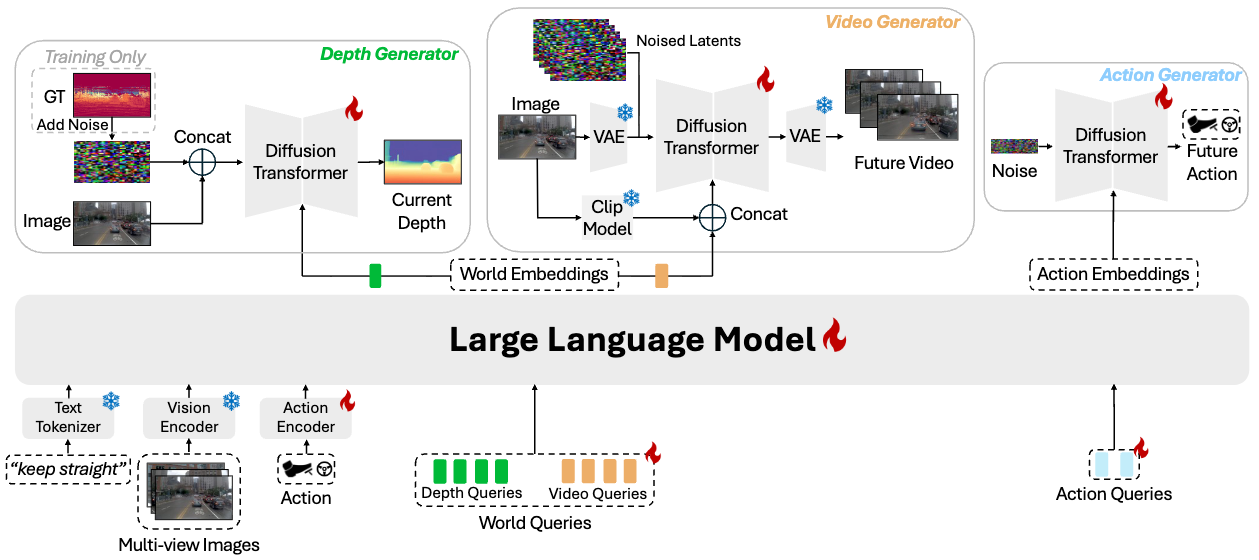
Depth Generator
Pixel-space diffusion transformer trained with flow-matching. Generates monocular depth as an explicit 3D scaffold, conditioned on world depth embeddings via cross-attention. Operates directly in pixel space for boundary fidelity.
Video Generator
Latent-space text-image-to-video diffusion transformer initialized from Wan-2.1. Conditioned on world video embeddings (which incorporate upstream depth cues) and a CLIP visual condition for appearance grounding. Generates 9-frame future videos at 144×256.
Action Generator
Standalone flow-matching diffusion transformer mapping noise to feasible future trajectories. Parameterized as (x, y, cos θ, sin θ) for smooth turn dynamics. Can operate independently for planning-only mode.